

西风 发自 凹非寺
量子位 | 公众号 QbitAI
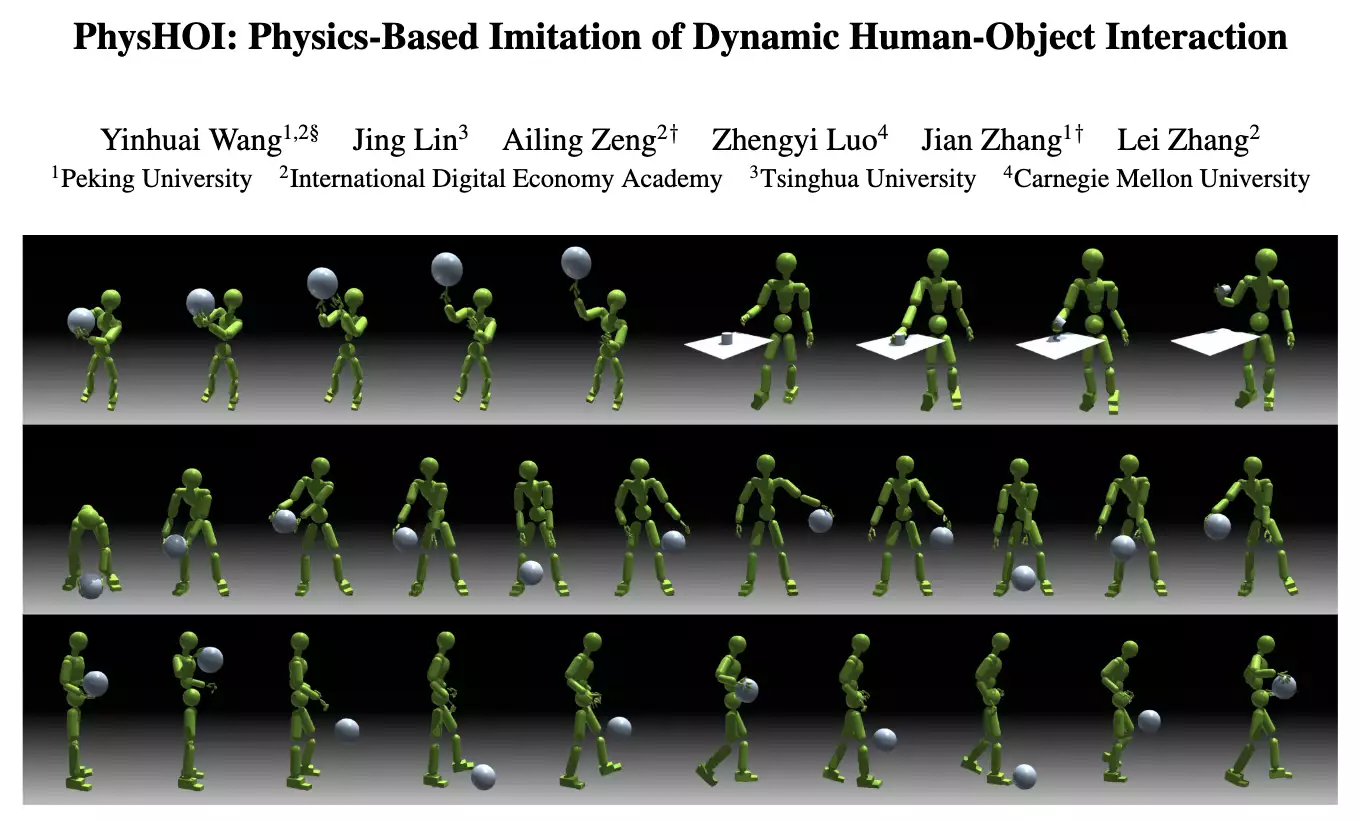
投篮、运球、手指转球…这个物理模拟人形机器人会打球:

会的招数还不少:

一通秀技下来,原来都是跟人学的,每个动作细节都精确复制:

这就是最近的一项名为PhysHOI的新研究,能够让物理模拟的人形机器人通过观看人与物体交互(HOI)的演示,学习并模仿这些动作和技巧。
重点是,PhysHOI无需为每个特定任务设定具体的奖励机制,机器人可以自主学习和适应。
而且机器人的身上总共有51x3个独立控制点,所以模仿起来能做到高度逼真。

一起来看具体是如何实现的。
模拟人形机器人变身「灌篮高手」
这项工作由来自北京大学、IDEA研究院、清华大学、卡内基梅隆大学的研究人员共同提出。
经研究人员介绍,此前大多数类似工作,存在模仿动作孤立、需特定任务的奖励、未涉及灵巧的全身运动等局限。

而他们提出的PhysHOI,应用动作捕捉技术提取HOI数据,然后使用模仿学习来学习人体运动和物体控制,解决了这些问题。
其中,HOI数据重要组成部分之一是涵盖了人体运动、物体运动、相对运动的运动学数据(Kinematic Data),记录了位置、速度、角度等信息。
另外,动态数据(Dynamic Data)反映了运动过程中的实时变动和更新,也很重要。

为了弥补HOI数据中动态信息的不足,研究人员引入了接触图(contact graph,CG)。
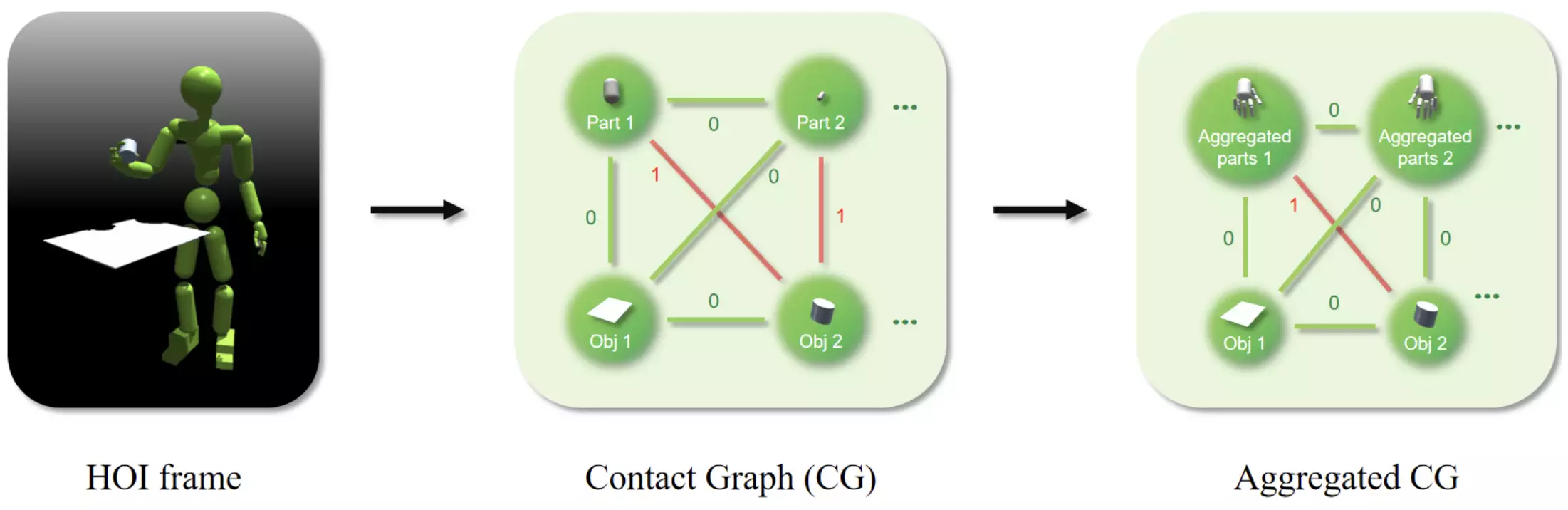
CG的节点由机器人的肢体部件和物体组成;每条边则是一个二进制接触标签,只表达“接触”或“不接触”两种状态。
此外,还可以将多个肢体部件放到一个节点中,形成一个聚合CG(Aggregated CG)。
具体来说,PhysHOI方法是:
首先通过运动捕捉获取参考HOI状态序列,包含人体运动、物体运动、交互图和接触图。

然后用第一帧的信息初始化物理模拟环境,构建包含当前模拟状态和下一个参考状态的系统状态。
接下来输入策略网络生成的动作控制人形机器人,物理模拟器根据动作更新场景中人体和物体的状态,计算包含运动匹配、接触图等多个方面的奖励。
利用奖励、状态和动作样本优化策略网络,采用更新后的策略网络开始新一轮的模拟过程,如此循环直至网络收敛,最终获得能够重现参考HOI技能的控制策略。
值得一提的是,研究人员在这当中设计了一个与任务无关的HOI模仿奖励,无需针对不同任务自定义奖励函数,包括体现运动匹配度的身体和物体奖励、反映接触正确性的接触图奖励,避免了使用错误身体部位接触物体等局部最优解。
接触图奖励是关键
研究人员在两个HOI数据集上测试了PhysHOI。
其中引入了BallPlay数据集,包含多种全身篮球技能。

研究人员在GRAB数据集的S8子集中选择了5个抓取案例,以及BallPlay数据集的8个篮球技能。
以此前的DeepMimic、AMP等方法作为基线,为公平比较,研究人员将其做了修改,以适应HOI模仿任务。
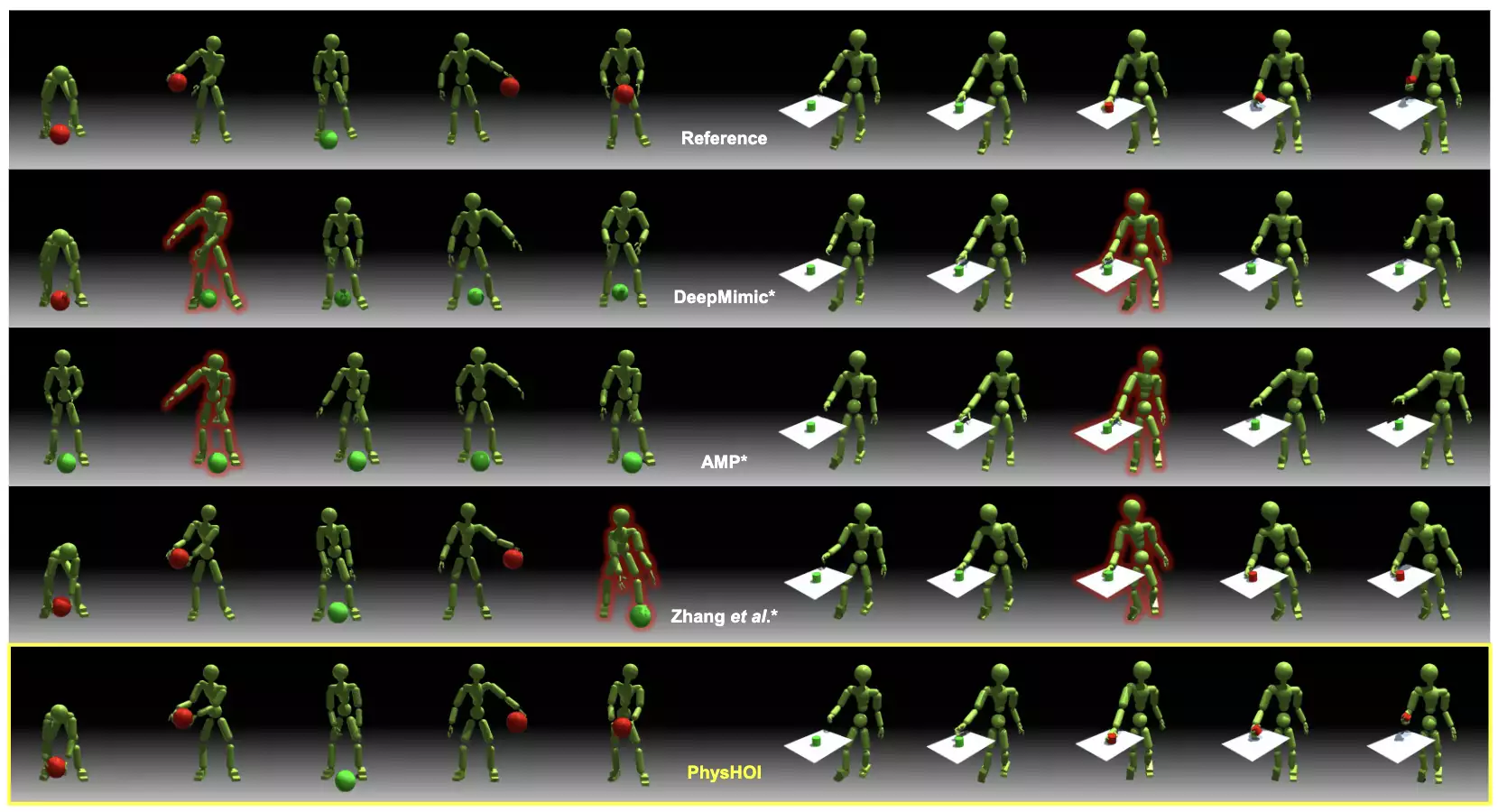
结果显示,以往只使用运动学奖励的方法无法准确复现交互,球会掉落或抓握失败。
而在接触图的指导下,PhysHOI成功进行了HOI模仿。
PhysHOI在两个数据集上都获得最高的成功率,分别为95.4%和82.4%,同时也取得最低的运动误差,显著优于其它方法。

消融研究表明,接触图奖励能有效避免只使用运动信息的方法陷入局部最优,指导机器人实现正确接触。

如果没有接触图奖励,人形机器人可能无法控制球,或者错误地使用身体其它部位控制球:

论文链接:https://arxiv.org/abs/2312.04393
— 完 —
量子位 QbitAI · 头条号签约






